llm.hunyuan.T1
| 中文 | English |
Reasoning Efficiency Redefined! Meet Tencent’s ‘Hunyuan-T1’—The First Mamba-Powered Ultra-Large Model
😄 blog | 💬 demo | 🔗 api | 📝 Contact
Reinforcement learning has pioneered a new Scaling paradigm in the post-training phase of large language models, a breakthrough that is increasingly attracting attention from the industry. With the successive release of OpenAI’s O-series models and DeepSeek R1, the excellent performance demonstrated by the models fully proves the crucial role of reinforcement learning in the optimization process
In mid-February this year, the Hunyuan team launched the Hunyuan T1-Preview (Hunyuan-Thinker-1-Preview) reasoning model based on the medium-scale Hunyuan base on the Tencent Yuanbao APP, bringing users an ultimate and rapid in-depth thinking experience.
Today, we are very pleased to announce that the in-depth thinking model of the Hunyuan large model series has been successfully upgraded to the Hunyuan-T1 official version , . This model is based on the TurboS fast-thinking base, the world’s first ultra-large-scale Hybrid-Transformer-Mamba MoE , large model released by us at the beginning of March. Through large-scale post-training, its reasoning ability has been significantly expanded and further aligned with human preferences.
Compared with the previous T1-preview model, Hunyuan-T1 has shown a significant overall performance improvement and is a leading cutting-edge strong reasoning large model in the industry.
Based on TurboS, T1 shows unique advantages in the direction of in-depth reasoning. TurboS’s long-text capture ability helps Turbo-S effectively solve the problems of context loss and long-distance information dependence often encountered in long-text reasoning. Secondly, its Mamba architecture specifically optimizes the processing ability of long sequences. Through an efficient computing method, it can ensure the ability to capture long-text information while significantly reducing the consumption of computing resources. Under the same deployment conditions, the decoding speed is 2 times faster.
In the post-training phase of the model, we invested 96.7% of our computing power in reinforcement learning training, focusing on improving pure reasoning ability and optimizing alignment with human preferences.
We collected world science and reasoning problems, covering mathematics/logic reasoning/science/code, etc. These data sets cover everything from basic mathematical reasoning to complex scientific problem solving. Combined with ground-truth real feedback, we ensure that the model can demonstrate excellent capabilities when facing various reasoning tasks.
In terms of training plans, we adopted a curriculum learning approach to gradually increase data difficulty while expanding the model’s context length in a step-by-step manner, enabling the model to improve its reasoning ability while learning to use tokens efficiently for reasoning.
Regarding the training strategy, we referred to classic reinforcement learning strategies such as data replay and periodic policy resetting, which significantly improved the long-term stability of model training by over 50%. During the alignment with human preferences phase, we adopted a unified reward system feedback scheme of self-rewarding (based on an early version of T1-preview to comprehensively evaluate and score the model’s output) + reward model, guiding the model to self-improve. The model shows richer content details and more efficient information in its responses.
In addition to achieving comparable or slightly better results than R1 on various public benchmarks such as MMLU-pro, CEval, AIME, Zebra Logic, and other Chinese and English knowledge and competition-level math and logical reasoning indicators, Hunyuan-T1 also performs on par with R1 in internal human evaluation datasets. It has a slight edge in cultural and creative instruction following, text summarization, and agent capabilities.
From the perspective of comprehensive evaluation metrics, the overall performance of Hunyuan-T1 can be on a par with first-class cutting-edge inference models. In terms of comprehensive ability evaluation, T1 ranks second only to O1 on MMLU-PRO, with a high score of 87.2. This test set covers questions from 14 fields such as humanities, social sciences, and science and engineering, mainly testing the model’s memory and understanding of extensive knowledge. Additionally, there is GPQA-diamond, which focuses on professional domain knowledge and complex scientific reasoning, mainly including doctoral-level difficult problems in physics, chemistry, and biology. T1 achieved a score of 69.3.
In the field of science and engineering, we tested scenarios that require strong reasoning abilities, such as coding, mathematics, and logical reasoning. In the code evaluation of LiveCodeBench , T1 reached a score of 64.9. Meanwhile, T1 also performs excellently in mathematics. Especially on MATH-500, it achieved an excellent score of 96.2, closely following DeepSeek R1, demonstrating T1’s comprehensive ability in solving math problems. Besides, T1 has shown very strong adaptability in multiple alignment tasks, instruction-following tasks, and tool utilization tasks. For example, T1 achieved a score of 91.9 **in the ArenaHard** task.
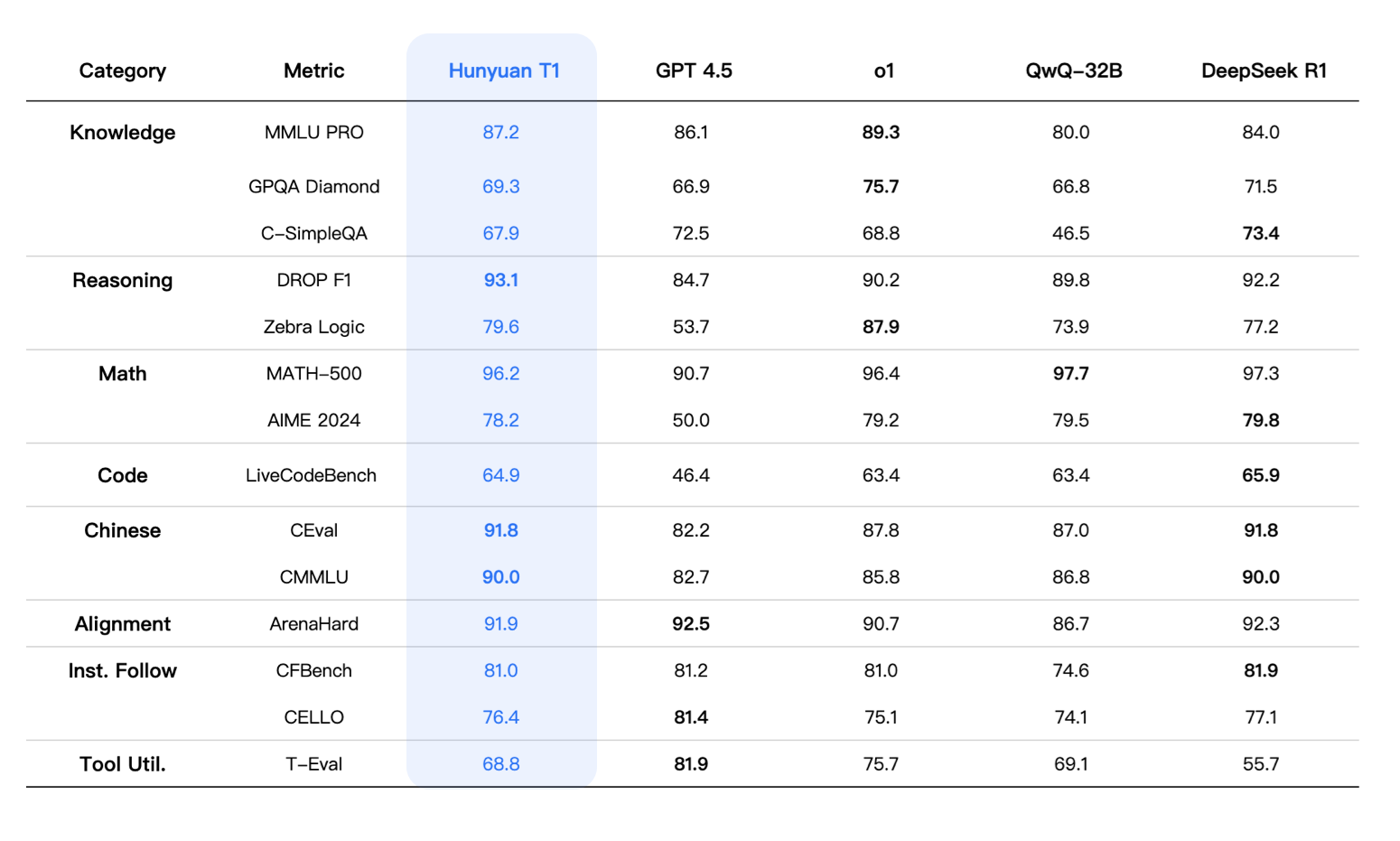

Note: The evaluation metrics of other models in the table are from official evaluation results. For the parts not included in the official evaluation results, they are from the results of the Hunyuan internal evaluation platform.